By Stevie Kiesel, Biodefense PhD Student
Did you know that since 1999 data has shown a strong correlation between the amount of crude oil the US imports from Norway and the number of drivers killed in collisions with railway trains? When the US imports more oil, more drivers are killed in these collisions. Don’t take my word for it, the proof is in this chart, backed by data from the Department of Energy and the Centers for Disease Control and Prevention!
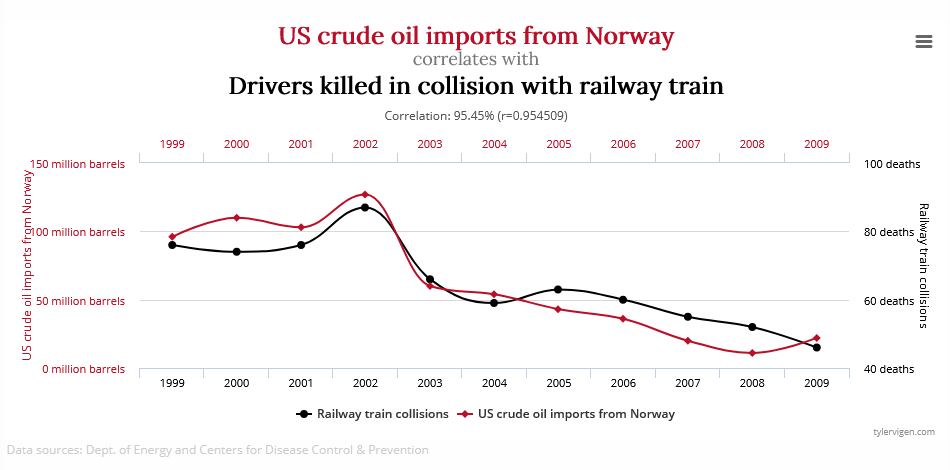
This correlation, of course, is just a coincidence between two unrelated variables. Even though the source data is legitimate, correlation in this case does not equal causation. This image comes from a website called Spurious Correlations, which parses publicly available data to show these types of meaningless, but visually captivating, graphics.
Analyzing data helps us better understand so many questions about the world, but data can also be misinterpreted or intentionally misused to promote a particular agenda. The ways that data can be misrepresented are virtually endless, from a misleading y-axis to inappropriate scaling to cherry-picking what data to include. For an egregious example of bad chart-making, take a look at this comparison of prevention services and abortions conducted by Planned Parenthood, presented by former Utah Representative Jason Chaffetz in 2015.
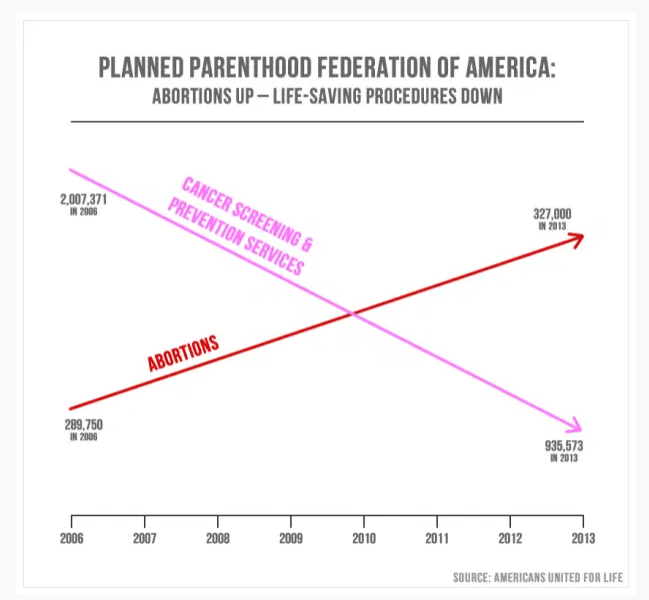
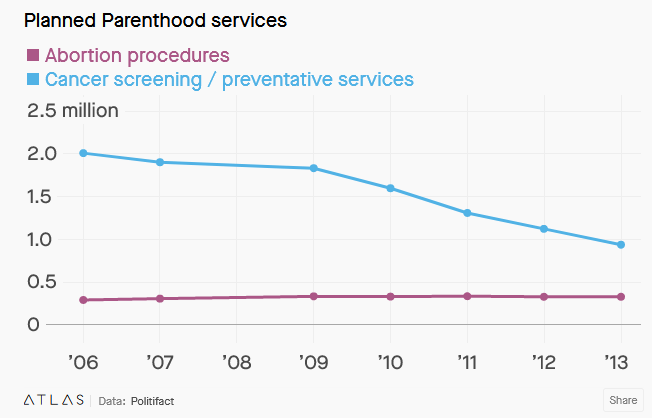
The Congressman explained his chart by saying it shows “the reduction in breast exams and…the increase in abortions.” And while those general trends may be accurate, in what universe is 935,573 cancer screenings a smaller number than 327,000 abortions? This is the kind of visual trickery you can get up to when you decide a y-axis isn’t necessary. The chart below shows the same data plotted in a more traditional (and accurate) way:
Politicians, media organizations, your uncle on Facebook – anyone can manipulate data and create a snazzy graphic to drive home their particular message. With the ongoing COVID-19 pandemic, such data skewing can be particularly dangerous, obscuring important trends and leading to counterproductive policy decisions. Such is the case even when bad visuals are not malicious. Take for example this visual from the Arkansas Department of Health, which is trying to make some kind of point about COVID-19 cases and preexisting health conditions:
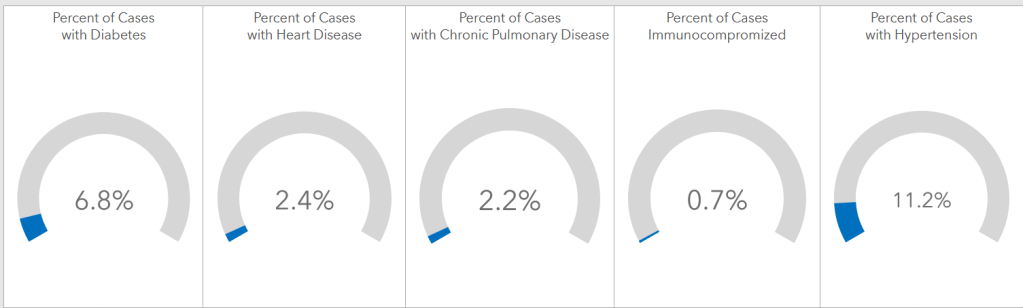
The choice to present the data as semi-circles is curious – it is assumed, but not stated, that these percentages are out of 100. Plotting these statistics on a bar graph, perhaps with a y-axis that goes from 0 to 10% rather than 0 to 100%, would allow readers to see more nuanced differences between these conditions. These graphics also lack the “so what.” A case refers to a person who is presumptively or confirmed positive for COVID-19. A comparison of the cases, hospitalizations, and deaths among the various conditions would provide much more useful insights about how other health issues impact the severity of the disease and a patient’s likelihood of surviving it.
Fortunately, while some in our government are misreading or misrepresenting COVID-19 data, other institutions are working to gather and analyze data in a systematic and defensible way. Toward this end, the Government Accountability Office (GAO) recently published a Technology Assessment GAO-20-635SP, COVID-19 Data Quality and Considerations for Modeling and Analysis. This assessment was undertaken to provide policymakers with context on the proper use and limitations of COVID-19 data and models. This report is a useful explanatory tool for understanding how data is gathered, aggregated, contextualized, presented, and updated.
The Centers for Disease Control and Prevention (CDC) relies on public health surveillance data that originate with health care providers, hospitals, and laboratories and then are reported up to the CDC through local public health agencies and state health departments. Reporting requirements are established at state and local levels, and notification to the CDC is voluntary. A standardized case definition for COVID-19 was not developed until April 5, 2020. Because of these factors as well as local variations (availability of tests and testing centers, contact tracing capabilities, etc.), data consistency is a challenge. Data completeness is another big challenge causing an undercount of the true number of cases (see page 7 of the GAO report). Lack of resources, asymptomatic or mild cases not seeking medical care, and timeliness of test results can all present challenges to obtaining complete COVID-19 data.
Another challenge comes from the failure to systematically collect demographic data. Local and state reporting requirements for this information were inconsistent until June 4, 2020, when the Department of Health and Human Service released new guidance that requires additional demographic data (race, ethnicity, age, and sex) to be reported with COVID-19 test results beginning August 1, 2020. Therefore, even though preliminary evidence suggests demographic disparities in the case load and severity of COVID-19, these data have only begun to be systematically provided for analysis.
The GAO report also provides helpful guidance on when to use certain measures and certain types of analyses. For example, this table shows when to use data on cases versus hospitalizations versus deaths:

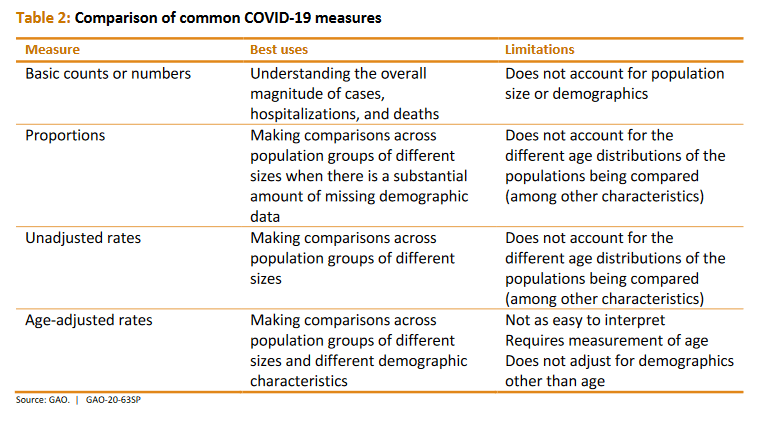
And this table highlights common methods for contextualizing data, when each method is most appropriate, and their respective limitations:
The report finishes with several recommendations to improve data collection, analysis, and reporting. First, researchers should examine deaths due to other or unspecified respiratory diseases (including pneumonia and the flu) during the pandemic to determine if some COVID-19 deaths had been miscategorized by analyzing whether higher-than-expected number of non-COVID-19 respiratory deaths were recorded during the pandemic. Second, researchers should examine higher-than-expected deaths from all causes during the pandemic (also called “excess deaths”), also to help address the issue of potential undercount of COVID-19 deaths. Third, in the longer term when data become available, researchers should compare higher-than-expected numbers of deaths from other causes to deaths from COVID-19 to get a better sense of the magnitude of deaths caused by COVID-19. And fourth, while efforts to improve forecasting model accuracy should continue, policymakers and researchers must understand that “during the outbreak of a new disease, models can be most helpful early in the response, but are most limited by a lack of data. Later in the outbreak, more data become available, but there is less time to implement an optimal response for ending the outbreak” (GAO report, page 26).

One thought on “Commentary – COVID-19 Data and Modeling: Applications and Limitations”